Selected Research and Software
Entity Resolution
Very often information about social entities is scattered across multiple databases. Combining that information into one database can result in enormous benefits for analysis, resulting in richer and more reliable conclusions. In most practical applications, however, analysts cannot simply link records across databases based on unique identifiers, such as social security numbers, either because they are not a part of some databases or are not available due to privacy concerns. In such cases, analysts need to use methods from statistical and computational science known as entity resolution (also called record linkage or de-duplication) to proceed with analysis. Entity resolution is not only a crucial task for social science and industrial applications, but is a challenging statistical and computational problem itself, because many databases contain errors (noise, lies, omissions, duplications, etc.), and the number of parameters to be estimated grows with the number of records. Building methods and algorithms for entity resolution that have public policy implications is at the core of my research. Case studies of my methods have been applied to the Syrian conflict, official statistics, voter registration data, and health care data, illustrating the flexibility and wide range of applicability of my methods to be used on data sets that are becoming increasingly more important in the health and social sciences.
Bayesian Entity Resolution
This paper proposes the first method, to our knowledge, to simultaneously perform entity resolution for more than two databases while propagating the uncertainty asso- ciated with the entity resolution process. Records are clustered to similar records using a latent variable model, where the underlying data is assumed to be corrupt, noisy, and dis- torted; such a distortion process is embedded into the model. The records are clustered using a data structure, called the linkage structure, which along with a Metropolis within Gibbs sampler, allows the posterior to be updated quickly.
Empirical Bayesian Entity Resolution (blink)
As in Steorts, Hall, Fienberg (2014, 2016), the entity resolution problem is framed by linking observed records to latent entities and representing the links and non- links via the linkage structure. The contributions of this paper are the following: The model allows one to model categorical data and text data. In order to allow for tractability of the conditional distributions, an empirically motivated approach is taken with regards to several priors. In addition, the distance function for the text data is arbitrary and can be chosen by the user to allow for utmost flexibility. Turning to the experiments, the model was evaluated on both synthetic and real data from Italian household surveys. In the case of the synthetic data, we make comparisons to semi-supervised methods that are commonly used in record linkage, namely logistic regression, Bayesian Adaptive Regression Trees (BART), and random forests, illustrating that our method does as well or better based upon the recall and precision (or false negative rate and false discovery rates). A sensitivity analysis is then performed for all assumed hyper-parameters in the model and a discussion is given regarding the sensitivity and robustness, which is a known problem in the entity resolution literature.
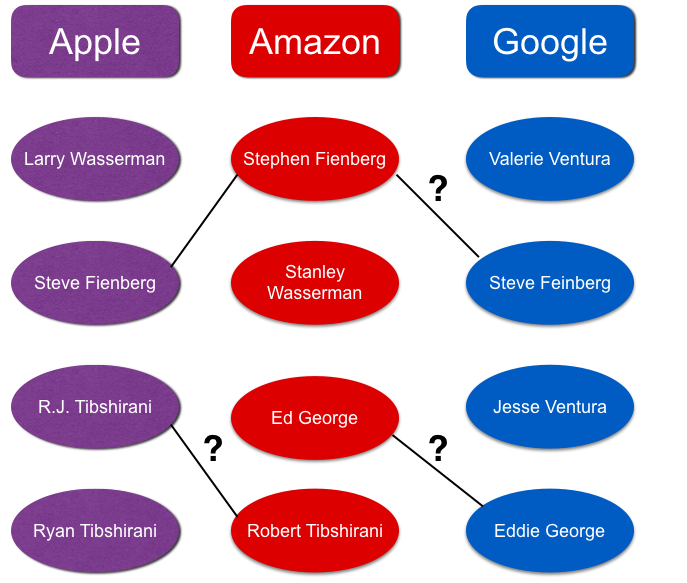
d-blink: Distributed End-to-End Bayesian Entity Resolution
Entity resolution (ER; also known as record linkage or de-duplication) is the process of merging noisy databases, often in the absence of unique identifiers. A major advancement in ER methodology has been the application of Bayesian generative models. Such models provide a natural framework for clustering records to unobserved (latent) entities, while providing rigorous quantification of uncertainty. Despite these advancements, existing models are severely limited in practice due to poor scaling, which is roughly quadratic in the number of records. This problem cannot be addressed using conventional blocking methods without compromising posterior correctness. In this paper, we propose ``distributed Bayesian linkage'' or dblink---the first scalable and distributed Bayesian model for ER, which jointly performs blocking and ER. Specifically, we propose an auxiliary variable representation, which induces a partition of the latent entities and records into blocks. We prove that our proposed auxiliary variable representation preserves the marginal posterior distribution over the model parameters. We propose a method for constructing well-balanced blocks based on k-d trees. We propose a distributed partially-collapsed Gibbs sampler to perform inference and demonstrate superior mixing times when compared to a standard Gibbs sampler. We propose algorithms for improving computational efficiency of the Gibbs updates which leverage indexing data structures and a novel perturbation sampling algorithm. Finally, we evaluate our proposed methodology on synthetic and real data sets, demonstrating efficiency gains in excess of 300 times when compared to existing non-distributed methods.
[paper][code][experiments]
Unique Entity Resolution
Estimation of death counts and associated standard errors are of great impor- tance in armed conflicts such as the ongoing violence in Syria, as well as historical conflicts in Guatemala, Peru, and elsewhere. Given a data set with records that have duplicated en- tities, our goal is to estimate the number of unique records with an overall computational cost drastically less than quadratic. To achieve this goal, we formalize it as approximating the number of connected components in a graph with sub-quadratic queries for edges. This proposal is first to describe efficient adaptive locality sensitive hashing on edges to estimate the connected components, where we show under realistic assumptions that our estimator is unbiased and has provably low variance. In addition, we provide empirical results on three real data sets as well as a case study on a subset of the Syrian conflict comparing to fundamental work done by the Human Rights Data Analysis Group (HRDAG) in 2014.
[paper]
Blocking Comparisons for Entity Resolution
The contributions of this paper are three fold. First, we review commonly used blocking techniques in both the computer science and statistics literature. Second, we pro- pose two new blocking techniques, one based upon random projections and another based upon locality sensitive hashing that preserves transitive connections of the graph. Third, we prove the computational complexity of all methods and give comparisons of all methods on simulated methods on errors rates and computational run time. The strengths and weakness of all methods are discussed for potential users in practice.
Microclustering
Conventional clustering models presume that the goal is to divide the data into a small number of high-probability clusters. Even if this is somewhat loosened to allow for a large number of clusters, each having low probability as in some Bayesian non-parametric models, every cluster still has strictly positive probability. This has two consequences as the number of observations grows. First, every cluster is observed infinitely often. Indeed, under exchangeability, observing a data point from a cluster generally makes it more prob- able to observe more data from that cluster in the future. Second, because every cluster is observed infinitely often, the usual asymptotic theory applies to inferring cluster proper- ties or parameters. Uncertainty about what each cluster is like shrinks to zero in the limit. First, we proposed the microclustering property, which addresses this problem. Second, we proposed a general set of models — Flexible Microclustering Models (FMMs) — which satisfy the microclustering property, and developed FMMs for record linkage tasks. Third, even the most efficient MCMC approaches are expected to converge slowly in very large and high-dimensional spaces. This is especially problematic for record linkage, since the number of latent variables to be inferred will grow with the number of records. Due to this, a new MCMC algorithm, the chaperones algorithm, was proposed and implemented in our paper. Finally, we illustrated our methodology, with comparisons to the Pitman-Yor process and the Dirichlet Process, for four experiments.
Canonicalization
As already mentioned, the goal of any ER task is to merge together large noisy databases to remove duplicated entities, often in the absence of a unique identifier. Records that are same are co-referent, and records that are not the same are non-referent. Much of the ER literature advocates a pipeline approach (Christen, 2012), which comprises of four main stages -- attribute alignment, blocking, entity resoluton, and canonicalization (fusion). In the canonicalization stage of the pipeline, one seeks to find the set of representative records as typically matched record pairs are mapped to consistent clusters, which are then used to produce a set of representative records to construct a data set without duplicate information. The original idea of canonicalization was introduced in the machine learning literature by Culotta et. al (2007), where the authors proposed semi-supervised methods for canonical record selection in the context of citation databases. The authors assumed that training data was available to perform canonicalization, and one approach they authors advocate for is one based upon strings, where an edit distance function is learned to find the most representative centroid. Unfortunately, the proposed methods are limiting in the user must tune many parameters of their model. For example, four parameters, or rather, costs, must be tuned, which heavily rely on the training data at hand. In addition, the proposed methods rely on cross validation that are limiting when either training data is not available or thought to be unreliable. In more recent work, Kaplan et. al (2020) have proposed two fully unsupervised methods for canonicalization, which crucially does not rely on training data. The authors go further to handle more realistic types of ER data such as numerical, categorical, ordinal, and string features. Finally, the authors allow the ER uncertainty to propagate naturally from the ER task into the canonicalization method. Both proposed methods by the aforementioned authors are scalable to large databases, with the second approach is available via open source code. In addition to work on solely canonicalization, there has been a large amount of work focusing on the relationship between downstream tasks, such as linear regression, after the ER task. This literature can be classified into single and two-stage approaches.
[arxiv paper][code]